PDF Chatbot
I have been trying to find a way to use ChatGPT to “chat” with a local collection of documents, ideally PDFs, TXTs and potentially other formats. It turns out there are a lot of YouTube videos on the topic…and a bunch of approaches, but it seems to basically come down to:
- Read the documents
- Convert them into “chunks” of text that can be ingested into GPT
- Convert these chunks into “embeddings”
- Add the “embeddings” to a Vector Data Store
- Ask a question
- Query the Vector Data Store for a semantic match
- Send that match to the LLM
- Present the answer to the user
- Potentially, add the question/answer pair to a buffer/memory to use in an ongoing conversation.
In a video by Alejandro Ao, he provided this miro.com illustration of the process:
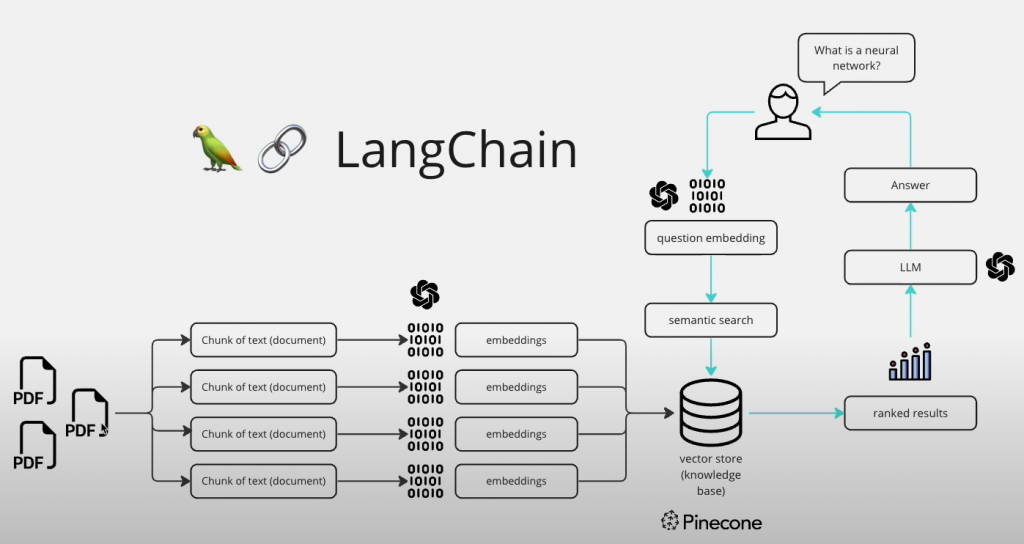
Alejandro credits the origin of the diagram to Benny Cheung here.
Here are the three videos that form the basis of my early research:
And their code repositories:
The three developers each take a similar approach, but their details are different. All three leverage LangChain functions. They generally use OpenAI for the Large Language Model (LLM). They use a number of options for the Vector Data Store:
- Pinecone
- FAISS
- ChromaBD
- DuckDB ( I see this mentioned but I am not certain it is a Vector Data Store)
The LLM is needed to answer the questions, but also to create the “embeddings” from the document chunks. This incurs a fee from OpenAI if you use their APIs (but the cost is honestly pretty low). You can use alternatives. Alejandro mentions using “instructor-xl” (intro) as it currently ranks higher than OpenAI (text-embedding-ada-002) on the Massive Text Embedding Benchmark leaderboard.
My changes
Some of the things I want to modify include
- Include a persistent vector database – Creating the embeddings is an “expensive” process. After experimentation, I would like to keep the database around so I can query later.
- Multiple databases – I have several different topics I want to research and want to keep these seperate.
- Question both the local docs as well as the broader training data available to models like GPT-4
- Provide a web GUI
PrivateGPT
As I have been tweaking with the various “Chat with your PDF” tutorials, I came across Matthew Berman’s video introduction to Iván Martínez’s PrivateGPT. While the idea here is to use local LLMs like GPT4All for a 100% private implementation, it has many of the features I was looking for. With the help of some community member ideas, I was able to tweak it to use OpenAI’s API for embeddings and queries. The bit it is missing (currently) is a WebGUI.
Another informational video was from Venelin Valkov on using GPT4All on free and local LLMs.